关于事务的一些理解
标签 : 分布式
1.柔性事务和刚性事务
柔性事务满足BASE理论
Base = Basically Available+Soft state+Eventually consistent 基本可用性+软状态+最终一致性。 核心思想是无法做到强一致性,但每个应用都可以根据自身的特点,采用适当方式达到最终一致性。 基本可用:可响应时间可损失、可功能损失。 软状态:允许系统数据存在中间状态,但不会影响到系统的整体可用性,即允许系统在不同节点的数据副本之间进行数据同步时存在延时。 最终一致性:要求系统数据副本最终能够一致,而不需要实时保证数据副本一致。最终一致性有5个变种:因果一致性、读己之所写(因果一致性特例)、会话一致性、单调读一致性、单调写一致性。在实际系统实践中,可以将若干变种结合起来。
CAP定理:CAP理论告诉我们:一个分布式系统不可能同时满足一致性(C:Consistency)、可用性(A:Availability)、分区容错性(P:Partition tolerance)这三个基本需求,并且最多只能满足其中的两项。
刚性事务满足ACID理论
ACID(Atomicity原子性、Consistency一致性、Isolation隔离性、Durability持久性)的分布式事务
2.分布式事务的概念
2.1 两阶段提交(2PC)型
2.2 事务补偿型(TCC事务)
补偿型的例子,在一个长事务( long-running )中 ,一个由两台服务器一起参与的事务,服务器A发起事务,服务器B参与事务,B的事务需要人工参与,所以处理时间可能很长。如果按照ACID的原则,要保持事务的隔离性、一致性,服务器A中发起的事务中使用到的事务资源将会被锁定,不允许其他应用访问到事务过程中的中间结果,直到整个事务被提交或者回滚。这就造成事务A中的资源被长时间锁定,系统的可用性将不可接受。 WS-BusinessActivity提供了一种基于补偿的long-running的事务处理模型。还是上面的例子,服务器A的事务如果执行顺利,那么事务A就先行提交,如果事务B也执行顺利,则事务B也提交,整个事务就算完成。但是如果事务B执行失败,事务B本身回滚,这时事务A已经被提交,所以需要执行一个补偿操作,将已经提交的事务A执行的操作作反操作,恢复到未执行前事务A的状态。这样的SAGA事务模型,是牺牲了一定的隔离性和一致性的,但是提高了long-running事务的可用性
2.3 三阶段提交(3pc)
canCommit preCommit doCommit
2.4 异步确保型
将一些同步阻塞的事务操作变为异步的操作,避免对数据库事务的争用,典型例子是热点账户异步记账、批量记账的处理
2.5 最大努力型
2.6 可靠事件
2.7 Sagas长事务
在Sagas事务模型中,一个长事务是由一个预先定义好执行顺序的子事务集合和他们对应的补偿子事务集合组成的。典型的一个完整的交易由T1、T2、……、Tn等多个业务活动组成,每个业务活动可以是本地操作、或者是远程操作,所有的业务活动在Sagas事务下要么全部成功,要么全部回滚,不存在中间状态
3. 总结
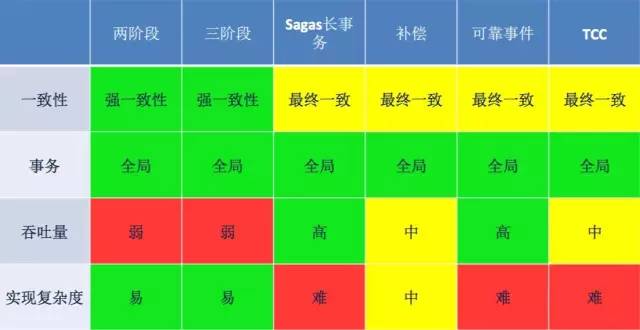
4. 最终一致性(eventually consistent)
对于一致性,可以分为从客户端和服务端两个不同的视角.从客户端来看,一致性主要指的是多并发访问时更新过的数据如何获取的问题.从服务端来看,则是更新如何复制分布到整个系统,以保证数据最终一致.一致性是因为有并发读写才有的问题,因此在理解一致性的问题时,一定要注意结合考虑并发读写的场景. 从客户端角度,多进程并发访问时,更新过的数据在不同进程如何获取的不同策略,决定了不同的一致性.对于关系型数据库,要求更新过的数据能被后续的访问都能看到,这是强一致性.如果能容忍后续的部分或者全部访问不到,则是弱一致性.如果经过一段时间后要求能访问到更新后的数据,则是最终一致性. 最终一致性根据更新数据后各进程访问到数据的时间和方式的不同,又可以区分为:
因果一致性.如果进程A通知进程B它已更新了一个数据项,那么进程B的后续访问将返回更新后的值,且一次写入将保证取代前一次写入.与进程A无因果关系的进程C的访问遵守一般的最终一致性规则.
“读己之所写(read-your-writes)”一致性.当进程A自己更新一个数据项之后,它总是访问到更新过的值,绝不会看到旧值.这是因果一致性模型的一个特例.
会话(Session)一致性.这是上一个模型的实用版本,它把访问存储系统的进程放到会话的上下文中.只要会话还存在,系统就保证“读己之所写”一致性.如果由于某些失败情形令会话终止,就要建立新的会话,而且系统的保证不会延续到新的会话.
单调(Monotonic)读一致性.如果进程已经看到过数据对象的某个值,那么任何后续访问都不会返回在那个值之前的值.
单调写一致性.系统保证来自同一个进程的写操作顺序执行.要是系统不能保证这种程度的一致性,就非常难以编程了.
上述最终一致性的不同方式可以进行组合,例如单调读一致性和读己之所写一致性就可以组合实现.并且从实践的角度来看,这两者的组合,读取自己更新的数据,和一旦读取到最新的版本不会再读取旧版本,对于此架构上的程序开发来说,会少很多额外的烦恼.
从服务端角度,如何尽快将更新后的数据分布到整个系统,降低达到最终一致性的时间窗口,是提高系统的可用度和用户体验非常重要的方面.对于分布式数据系统:
N — 数据复制的份 W — 更新数据时需要保证写完成的节点数 R — 读取数据的时候需要读取的节点数
如果W+R>N,写的节点和读的节点重叠,则是强一致性.例如对于典型的一主一备同步复制的关系型数据库,N=2,W=2,R=1,则不管读的是主库还是备库的数据,都是一致的.
如果W+R<=N,则是弱一致性.例如对于一主一备异步复制的关系型数据库,N=2,W=1,R=1,则如果读的是备库,就可能无法读取主库已经更新过的数据,所以是弱一致性.
对于分布式系统,为了保证高可用性,一般设置N>=3.不同的N,W,R组合,是在可用性和一致性之间取一个平衡,以适应不同的应用场景.
如果N=W,R=1,任何一个写节点失效,都会导致写失败,因此可用性会降低,但是由于数据分布的N个节点是同步写入的,因此可以保证强一致性.* 如果N=R,W=1,只需要一个节点写入成功即可,写性能和可用性都比较高.但是读取其他节点的进程可能不能获取更新后的数据,因此是弱一致性.这种情况下,如果W<(N+1)/2,并且写入的节点不重叠的话,则会存在写冲突
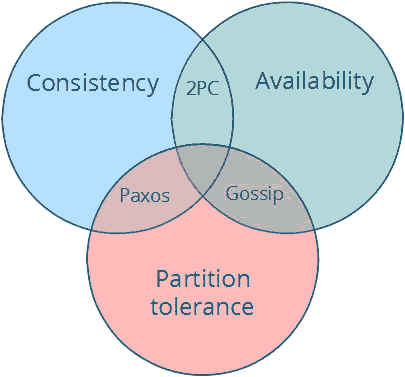
CA (consistency高一致性 + availability高可用性). 使用2pc 两阶段事务提交来保证。其缺点无法实现分区容错性,一旦某个操作失败,整个系统就出错,无法容忍(水至清则无鱼)。 CP (consistency高一致性 + partition tolerance分区容错性). 使用Paxos来保证,可用性降低。 AP (availability高可用性 + partition tolerance分区容错性). 使用Gossip等实现最终一致性,如Dynamo.