大数据学习-1
1 hadoop生态体系概念理解
- HDFS:HDFS是一种分布式文件系统层,可对集群节点间的存储和复制进行协调。HDFS确保了无法避免的节点故障发生后数据依然可用,可将其用作数据来源,可用于存储中间态的处理结果,并可存储计算的最终结果。
- YARN:YARN是Yet Another Resource Negotiator(另一个资源管理器)的缩写,可充当Hadoop堆栈的集群协调组件。该组件负责协调并管理底层资源和调度作业的运行。通过充当集群资源的接口,YARN使得用户能在Hadoop集群中使用比以往的迭代方式运行更多类型的工作负载。
- MapReduce:MapReduce是Hadoop的原生批处理引擎。
批处理 批处理模式中使用的数据集通常符合下列特征
- 有界:批处理数据集代表数据的有限集合
- 持久:数据通常始终存储在某种类型的持久存储位置中
- 大量:批处理操作通常是处理极为海量数据集的唯一方法
批处理非常适合需要访问全套记录才能完成的计算工作。例如在计算总数和平均数时,必须将数据集作为一个整体加以处理,而不能将其视作多条记录的集合。这些操作要求在计算进行过程中数据维持自己的状态。需要处理大量数据的任务通常最适合用批处理操作进行处理。无论直接从持久存储设备处理数据集,或首先将数据集载入内存,批处理系统在设计过程中就充分考虑了数据的量,可提供充足的处理资源。由于批处理在应对大量持久数据方面的表现极为出色,因此经常被用于对历史数据进行分析。 大量数据的处理需要付出大量时间,因此批处理不适合对处理时间要求较高的场合。
批处理模式 Hadoop的处理功能来自MapReduce引擎。MapReduce的处理技术符合使用键值对的map、shuffle、reduce算法要求。基本处理过程包括:
- 从HDFS文件系统读取数据集
- 将数据集拆分成小块并分配给所有可用节点
- 针对每个节点上的数据子集进行计算(计算的中间态结果会重新写入HDFS)
- 重新分配中间态结果并按照键进行分组
- 通过对每个节点计算的结果进行汇总和组合对每个键的值进行“Reducing”
- 将计算而来的最终结果重新写入 HDFS
1-1 Hadoop开源项目、安装配置
Hadoop cluster in one of the three supported modes:
Local (Standalone) Mode
Pseudo-Distributed Mode
Fully-Distributed Mode
The project includes these modules:
- Hadoop Common: The common utilities that support the other Hadoop modules.
- Hadoop Distributed File System (HDFS™): A distributed file system that provides high-throughput access to application data.
- Hadoop YARN: A framework for job scheduling and cluster resource management.
- Hadoop MapReduce: A YARN-based system for parallel processing of large data sets.
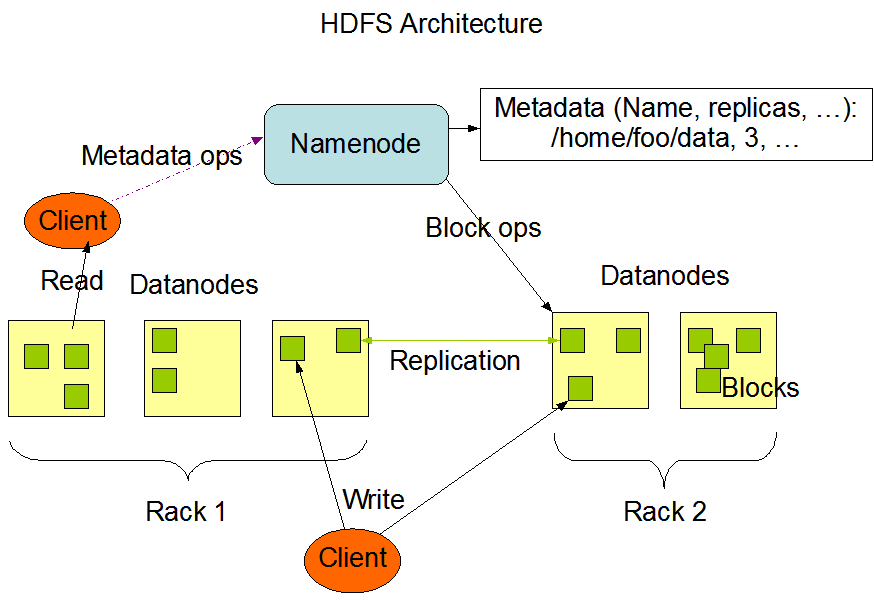
一个HDFS集群主要由一个NameNode和很多个Datanode组成:Namenode管理文件系统的元数据,而Datanode存储了实际的数据
https://hadoop.apache.org/docs/current/
http://www.powerxing.com/install-hadoop/
此外,伪分布式虽然只需要配置 fs.defaultFS 和 dfs.replication 就可以运行(官方教程如此),不过若没有配置 hadoop.tmp.dir 参数,则默认使用的临时目录为 /tmp/hadoo-hadoop,而这个目录在重启时有可能被系统清理掉,导致必须重新执行 format 才行。所以我们进行了设置,同时也指定 dfs.namenode.name.dir 和 dfs.datanode.data.dir,否则在接下来的步骤中可能会出错。 —-
1-2 MapReduce快速入门
YARN 是从 MapReduce 中分离出来的,负责资源管理与任务调度。YARN 运行于 MapReduce 之上,提供了高可用性、高扩展性
Make the HDFS directories required to execute MapReduce jobs:
$ bin/hdfs dfs -mkdir /user
$ bin/hdfs dfs -mkdir /user/kai
Copy the input files into the distributed filesystem:
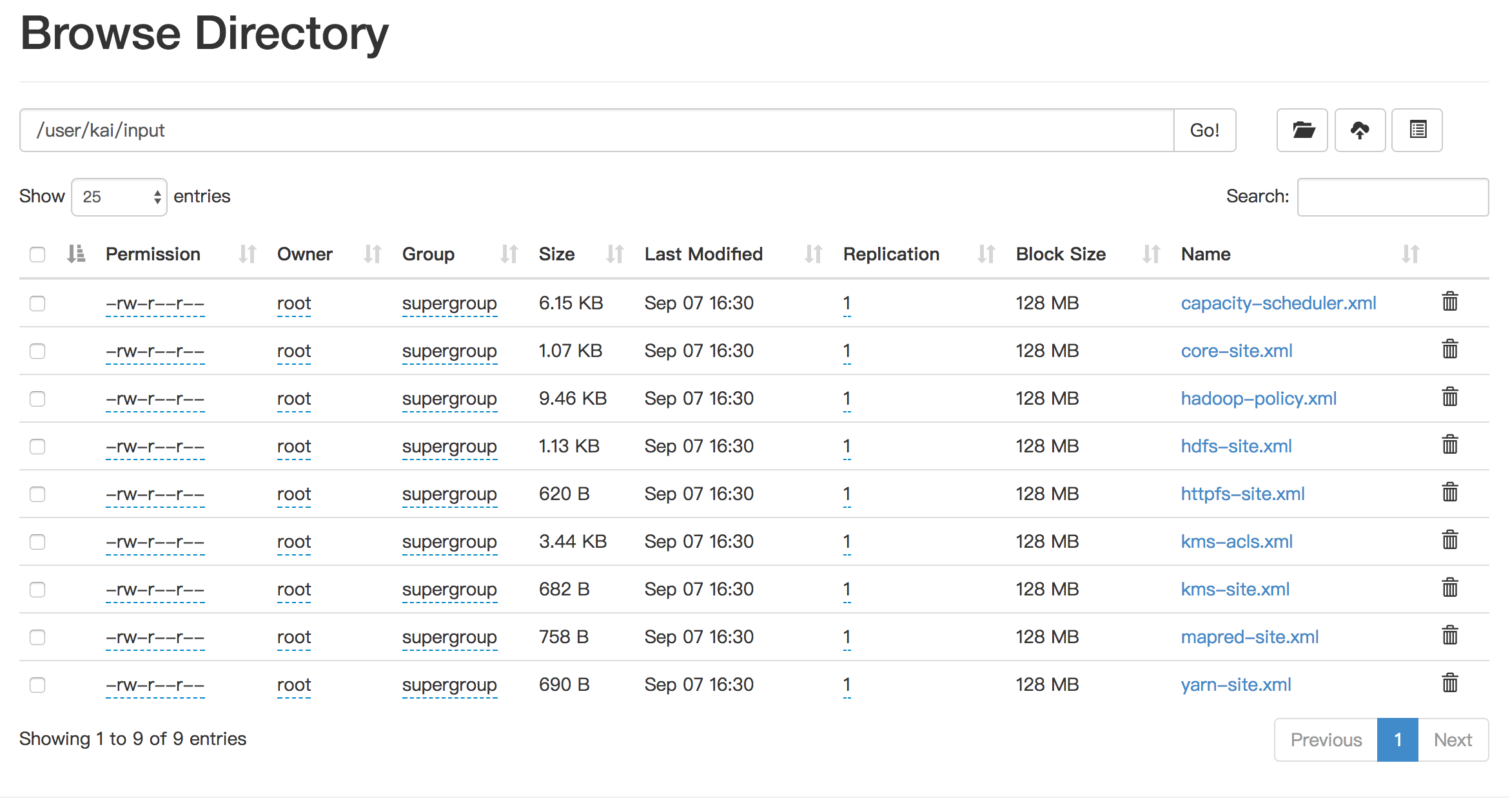
$ bin/hdfs dfs -mkdir /user/kai/input
$ bin/hdfs dfs -put etc/hadoop/*.xml /user/kai/input
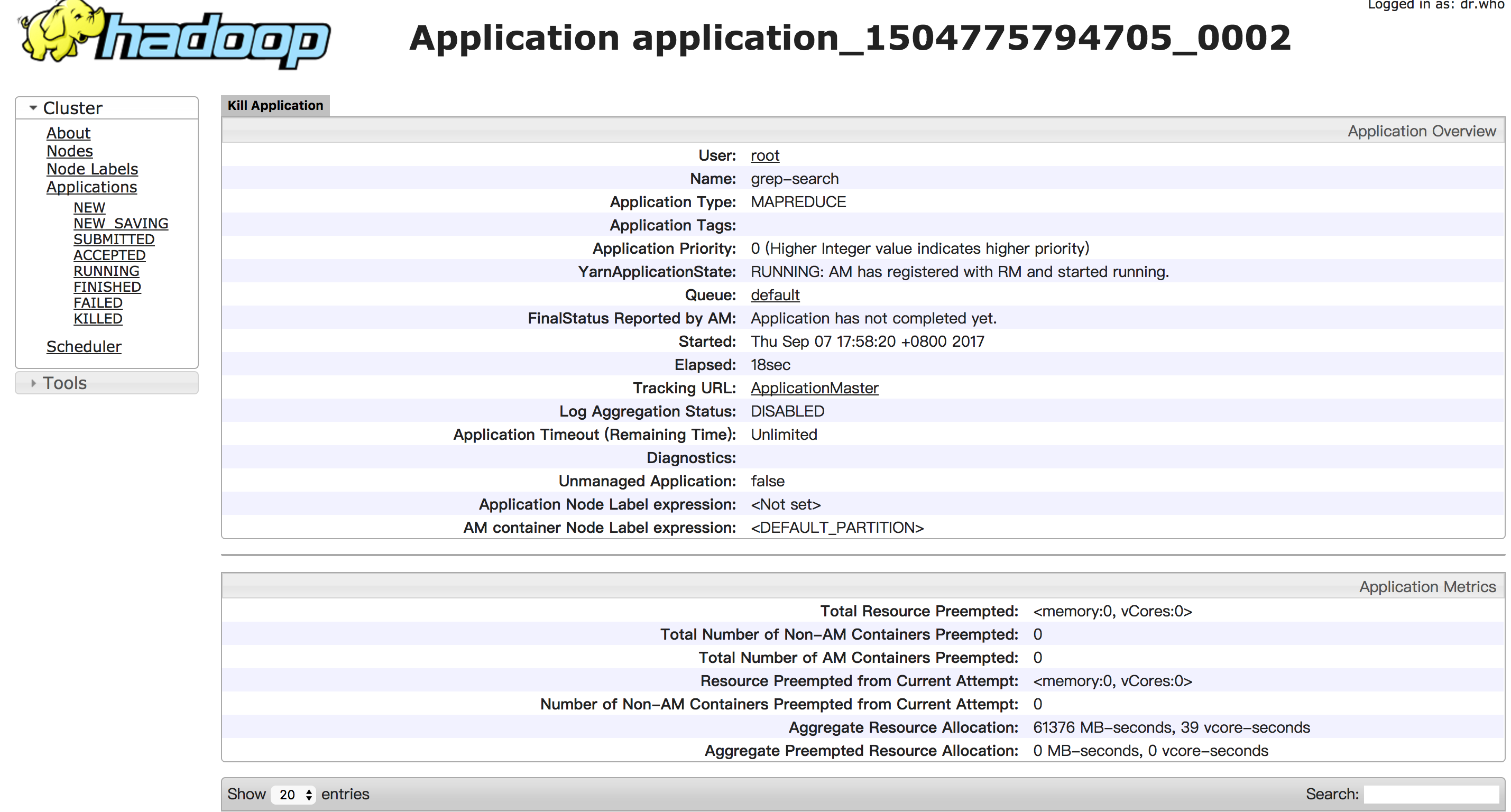
Run some of the examples provided:
$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.0.0-alpha4.jar grep /user/kai/input /user/kai/output 'dfs[a-z.]+'
root@kai:/opt/hadoop/hadoop/bin# ./hdfs dfs -cat /user/kai/output/*
1 dfsadmin
1 dfs.replication
1 dfs.namenode.name.dir
1 dfs.datanode.data.dir
root@kai:/opt/hadoop/hadoop/bin#
Start ResourceManager daemon and NodeManager daemon:
$ sbin/start-yarn.sh
Browse the web interface for the ResourceManager; by default it is available at:
ResourceManager - http://localhost:8088/
./sbin/mr-jobhistory-daemon.sh start historyserver
开启历史服务器,才能在Web中查看任务运行情况